
On a broad level, there are 2 methods for domain adaptation in Deep CNN type networks:
-
Correlation Alignment: Aligning the global statistics of source and target domain (handcrafted transformation).
-
Adversarial Alignment: Learns to form domain-invariant representations (learnt transformation).
Adversarial Alignment
Reading:
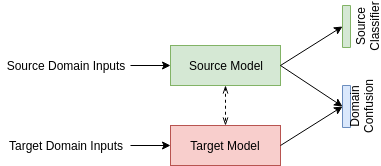
-
The source and target models can be same or different. To make them same, we use the weight tying concept in CNNs. Or we can tie only some layers.
-
The classification loss is only on source domain. We can also add it on target domain if we have data (semi-supervised DA).
-
The domain confusion loss can be of different types:
-
Adversarial loss: Add a classifier that learns to distinguish between the 2 domains. However, reverse the gradient going into the main network. Problem: The loss is not good enough. Suppose it learns to distinguish perfectly, and then reverses its decision. That will perform well on this loss but not help us.
-
GAN Loss: Intuitively, this is like matching a varying fake distribution to a constant real distribution. It only penalizes classification of target class, leaving the source feature distribution as it is (unless tied weights I guess).
-
Confusion Objective: Adversarial Loss + Reverse Adversarial Loss.
-
Ideas:
-
Keep a pretrained CNN and a new CNN initialised with pretrained CNN, with top few layers unfrozen. Learn a GAN loss and only propogate it in the new model. We can replace GAN Loss with pairwise L2 loss also.
-
DANN: Pretrained CNN + All weights tied. Learn domain invariance but keep a classification loss to ensure representations stay meaningful.
Papers:
BatchNorm based Alignment
Reading:
-
Both shallow layers and deep layers of the DNN are influenced by domain shift. Domain adaptation by manipulating the output layer alone is not enough.
-
The statistics of BN layer contain the traits of the data domain.
Method:
- Compute mean and var of target domain. While testing use target domain mean and variance instead of source domain.
Ideas:
-
Visualize mean and variance for each mini-batch for each layer for both datasets.
-
If they come to be very different for the 2 datasets, then the hypothesis in the paper is true.
Unified Deep Supervised Domain Adaptation and Generalization
This is for supervised domain alignment with scarse target data.
Reading:
Conceptually, we try to bring source and target domain features closer for points in same class, and try to separate the points in source and target domains for different classes.
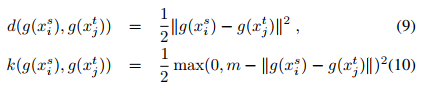
The $d$ loss is for points in same class. The $k$ loss is for points in different classes.
Ideas:
-
Label some points in target domain. Now fine-tune the last layer of CNN with 4 objectives: 2 Classification losses and 2 feature distance losses.
-
Keep 2 networks - fixed pretrained and fine tune last layer of the other (init with pretrained). Train with cls loss on 2nd + 2 feature distance losses between 1st and second.
CORAL and DEEP CORAL
The idea is to align second order statistics (Covariance) of source and target domains. I don’t think this will work with scarce target domain as there are too little target images compared to source.
Joint Geometrical and Statistical Alignment for Visual Domain Adaptation
They haven’t compared their approach to any adversarial approach.