
In this post I am reviewing some of the papers mentioned on the MIT Saliency Benchmark website.
(Sorted Reverse Chronologically)
What is Visual Saliency Prediction?
Humans make several eye movements per second, bringing the things they want to see into focus. The problem of predicting fixation locations given the image the observer is viewing is called saliency prediction.
Predicting Human Eye Fixations via an LSTM-based Saliency Attentive Model
Marcella Cornia, Lorenzo Baraldi, Giuseppe Serra, and Rita Cucchiara; 17 Mar 2017
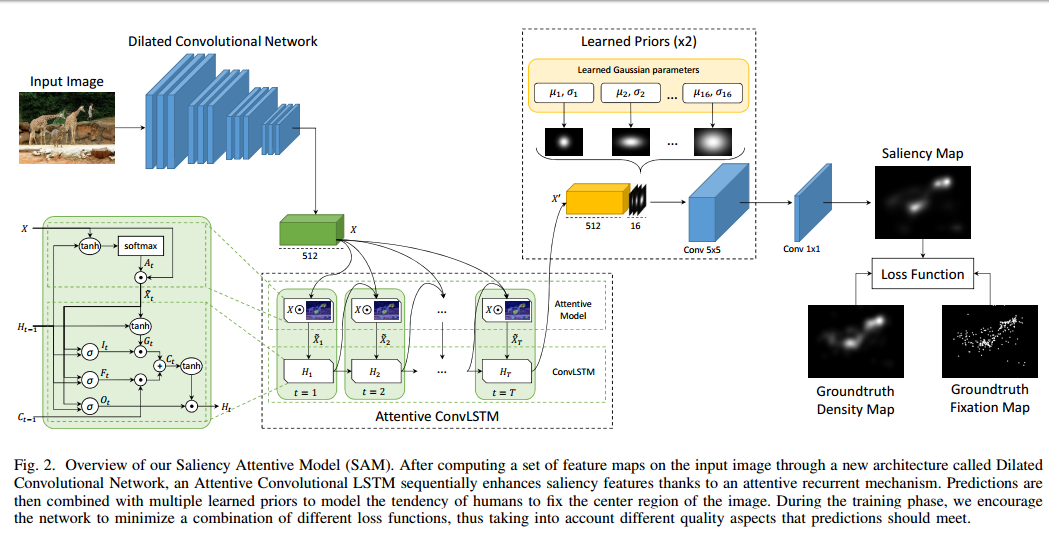
Related Work:
-
Traditional: by defining features that capture low-level cues such as color, contrast and texture or semantic concepts such as faces, people and text.
-
Deep Learning: variants of feed-forward architectures with various objectives, architectures, tricks.
Architecture
-
Dilated Convolutional Network: One of the main drawbacks of using CNNs to extract features for saliency prediction is that they considerably rescale the input image during the feature extraction phase.
-
ResNet-50: ”..we remove the stride and introduce dilated convolutions in the last two blocks. In particular, we introduce holes of size 1 in the kernels of the block conv4 and holes of size 22 − 1 = 3 in the kernels of the block conv5…“
-
VGG-16: ”..we remove the last max-pooling layer and we set the stride to 1 in the last but one. Besides, we introduce dilated convolutions (with hole size 1) in the last convolutional block.”
-
-
Attentive Convolutional LSTM: This part is used to iteratively refine the saliency map.
ConvLSTM is an LSTM in which dot product is replaced by Convolution layer. Attention mechanism is incorporated by adding another branch to the LSTM output, which predicts an attention map which is multiplied to the output feature map.
-
Learned Priors: Gaussian feature maps are appended to the 512 refined output feature maps obtained. The parameters of these gaussians (mean, std) are learnt by backpropogation.
-
Loss functions: Sum of Normalized Scanpath Saliency (NSS), the Linear Correlation Coefficient (CC) and the Kullback-Leibler Divergence (KL-Div) losses.
Comments
This is the most latest paper so they use the good things from all earlier papers and have good training/testing strategies.
SalGAN: Visual Saliency Prediction with Generative Adversarial Networks
Junting Pan, Elisa Sayrol and Xavier Giro-i-Nieto, Cristian Canton Ferrer, Jordi Torres, Kevin McGuiness and Noel E. O’Connor; 9 Jan 2017
Architecture
Generator is initialised with pretrained VGG.
Training
“At train time, we first bootstrap the generator function by training for 15 epochs using only BCE, which is computed with respect to the downsampled output and ground truth saliency. After this, we add the discriminator and begin adversarial training.”
A Deep Spatial Contextual Long-term Recurrent Convolutional Network for Saliency Detection
Nian Liu, Junwei Han; 6 Oct 2016
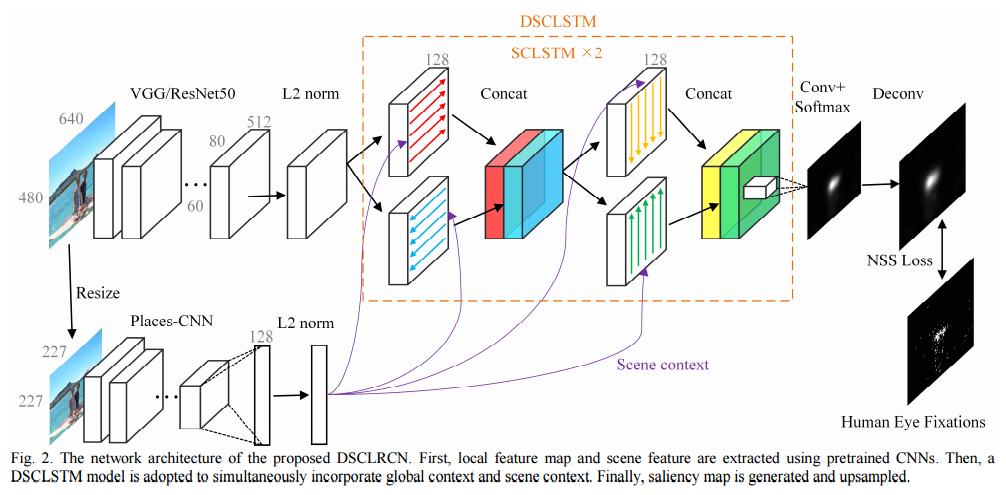
Architecture
They run LSTM on spatial feature vectors from left to right and top to bottom.
Motivation/Explanation
“… cortical lateral inhibition mechanisms in human visual system suggest that neighboring similar features can inhibit each other via specific, anatomically defined interconnections … different spatial locations in visual scenes should be considered holistically in visual attention, instead of only considering local regions in local contrast inference.”
DeepGaze II: Reading fixations from deep features trained on object recognition
Matthias Kümmerer, Thomas S. A. Wallis, Matthias Bethge; October 6, 2016
Architecture
See figure and its caption above.
They also say this about their architecture:
“Why does DeepGaze II perform better relative to other models that also use deep features? We believe this could be because, at least in part, we do not retrain the VGG features. While this reduces the model space, it also greatly reduces the number of parameters that must be learned from data, reducing the chance of overfitting. Furthermore, since we only use 1 × 1 convolutions on top of this, we cannot learn new features that are substantially different from VGG: only a pointwise nonlinearity is possible.”
Training
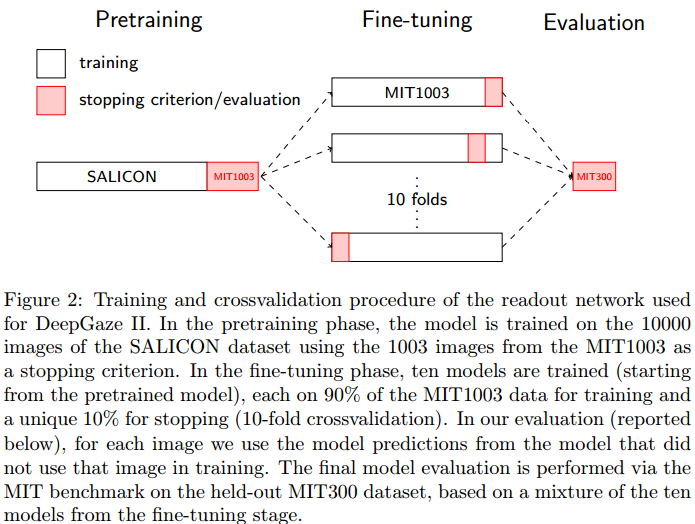
The paper uses a complicated training procedure, as shown above. They also say that “Training on the SALICON dataset marginally improved performance. Combining SALICON pretraining with the VGG features yields the largest intermediate model performance improvement.”
Comments
Their model and training procedure seem to be VERY complicated and hand-tuned. The ideas of using cross-entropy loss on target, and of center bias are good. Using a combination of lower and higher layers must have been important.
SALICON: Reducing the Semantic Gap in Saliency Prediction by Adapting Deep Neural Networks
Xun Huang, Chengyao Shen, Xavier Boix, Qi Zhao; 18 February 2016
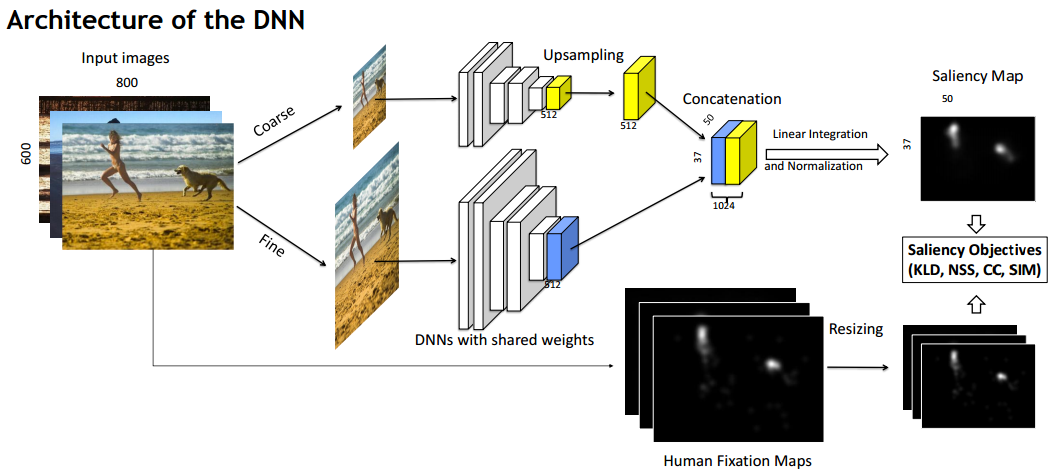
Architecture:
Important points: Fine-tuning and multi-scale
They say: We initialize the parameters of the DNN to the pretrained parameters in ImageNet, and then, we learn end-to-end the parameters of all the architecture.
Saliency Evaluation Objectives:
They say: We use 4 evaluation metrics as objective functions of the back-propagation, which are NSS, CC, KLD and Sim. These evaluation metrics have a derivative that can be used by the gradient descend of back-propagation. In the experiments we show that the objective function of KLD achieves a good compromise in all evaluation metrics we use.
Comments:
Multi-scale and experimenting with different objective functions are good ideas.
Check out the datasets referred to in the paper.
DeepFix: A Fully Convolutional Neural Network for predicting Human Eye Fixations
Srinivas S S Kruthiventi, Kumar Ayush, R. Venkatesh Babu; 10 Oct 2015
Interesting that they don’t have much novelty except the Location biased convolution layers and yet are close to best in the MIT Saliency Leaderboard. Is center-bias so important, or are their gains more from Inception like architecture?
Key points:
-
Large depth - to enable the extraction of complex semantic features
-
Kernels of different sizes operating in parallel - to characterize the object semantics simultaneously at multiple scales (like Inception)
-
Kernels with large receptive fields - for capturing the global context
-
Location biased convolutional layers - for learning location dependent patterns such as the centre-bias present in eye fixations - If we had CxHxW feature maps, it makes them (C+16)xHxW and the 16 channels are fixed centre bias maps.